
ナウトのエンジニアリング:わき見運転の検知を可能とするディープラーニング
人工知能(AI)がさまざまな業界に変革をもたらし始めています。その中で最も著しい変化が見られるのが自動車業界です。自動運転車が数多くの見出しを飾っていますが、人間のドライバーが不要になるのはまだ何年も先のことである、というのが大多数の専門家の共通した見解です。NHTSAによると、アメリカでは2017年だけで37,000人以上の人が自動車衝突事故で命を落としています。ナウトは目の前の命を救う一助となる、次世代型インテリジェント安全運転システムの開発を目標の1つに掲げています。
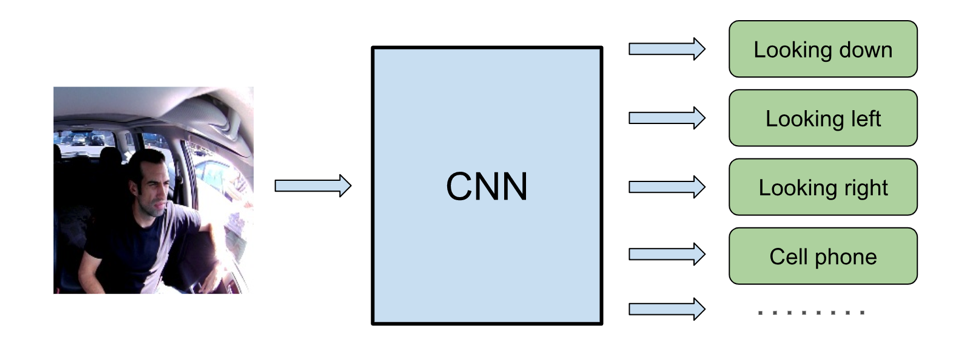
わき見運転の検知
効果的かつインテリジェントな安全運転システムは、ドライバーの道路に対する集中度を、非常に高い精度で検知します。従来、このようなタスクは、顔や目の動きを追跡するアルゴリズムの開発でまかなわれてきました。ところが、このようなアルゴリズムは、ドライバーの眼の形や光の状態、アクセサリやオクルージョンなど、実環境に潜むさまざまな条件に対応することが難しく、多くの場合苦戦を強いられてきました。近年ではディープラーニングが登場し、イメージ分類やコンピュータビジョン関連タスクの飛躍的な進歩を支えています。ディープラーニングモデルは通常、「教師あり学習」に設定され、大量のラベルや学習用データを使ってトレーニングされています。精度の高いモデルを作成する際、最も重要となるのがデータです。ナウトは、コネクテッドカメラのネットワークを進化させ続けることで、大量かつ多様な実環境データに対応し、対象データの抽出を可能にしています。
データの重要性
機械学習プロジェクトを導入する場合、必要なデータ量、その収集方法、ラベル付けに関するガイドラインなどについて決めておく必要があります。実環境でのプロジェクトの成功は、多くの場合、モデルやアルゴリズムの選択のほか、使用するデータに依存します。わき見運転のリアルタイム検知など、データの一貫性が低いタスクの場合(たとえば、「止まれ」の標識を検知する場合とは異なり)、特にデータが重要となります。ナウトのカメラネットワークでキャプチャし、AI処理された映像データ(1億5千万マイルに相当)を利用することで、収集すべきデータやラベル付けの方法など、導入時に必要な重要事項についてインサイトを得ることができます。その効果を上げるためには、アクティブ・ラーニング・メソッドを採用することが重要です。
アクティブラーニングを使った比較的シンプルな方法として、モデルを使用して予測信頼度が低いインスタンスを特定する、というものがあります。生徒(モデル)が先生(人間のラベル付け担当者)に分からない問題の解き方を質問するようなイメージです。さらに、多様なデータが最適な方法でキャプチャされるよう、データをサンプリングする方法を検討します。同じ区間を周回している自動車のデータだけで自動運転車をトレーニングすべきでないのと同様に、ドライバーを限定してわき見運転検知モデルを開発すべきではありません。多様なドライバーから等しくデータをサンプリングすることが、非常に重要になるのです。
マルチラベル分類
汎用性の高い視線/顔追跡プログラムを開発することは、ディープラーニングにとっても難しい課題です。視線方向を正確に把握してラベル付けするには、サングラスや帽子で目が覆われている場合について検討する必要があります。合成データを使用することもできますが、眼の形、体格、カメラの位置など、異なる条件を備えたドライバーを一般化することは簡単ではありません。ナウトはこれらを踏まえ、この課題をよりシンプルにとらえて分類しています。つまり、リアルタイムわき見運転検知に使用する区分を利用するのです。「下を見る」や「左/右を見る」などの区分は、定義が明確でラベル付けも簡単なため、ディープニューラルネットワークのエンドツーエンドのトレーニングに使用することが可能です。また、わき見運転検知を視線の動きに限定せず、携帯電話の使用やコンソールの操作など、その他の兆候にも拡大することも重要です。マルチタスクラーニングは、共通のニューラルネットワークを使うことで、同時にさまざまな結果を予測することができます。実際、ラベルを増やすことでトレーニング全体を改善するだけなく、他の関連ラベルの精度も向上させることができるのです。
時間と共に変化するコンテクストの学習
ドライバーのわき見運転は、直観的に、一定時間に発生する複数の行動をもとに定義されます。1枚のフレームだけでは、得られる情報が限られているからです。人間のラベル付け担当者も、映像を巻き戻して複数のフレームを確認し、基準値を決めています。現在では、回帰型ニューラルネットワーク(Recurrent Neural Networks;RNN)や長期短期記憶(Long Short-Term Memory;LSTM)ネットワークなど、一部の一般的な時間モデル向けディープニューラルネットワークはさまざまな用途に適用され、成功しています。主な適用例は、音声信号を使った音声認識です。ところが、これらのネットワークを視覚データに適用することは、さらに難しく、特に、演算リソースが制限されたリアルタイムアプリケーションでは一層困難といえます。
Siamese(シャム)ネットワークという、知名度は低いものの、時間情報の埋め込みが可能なネットワークがあります。このネットワークは重み共有を利用し、イメージ間の類似性を予測することで、2つのイメージを一緒にトレーニングすることができます。類似性は、学習したタスクに最も関連性のある特徴ごとに定義します。
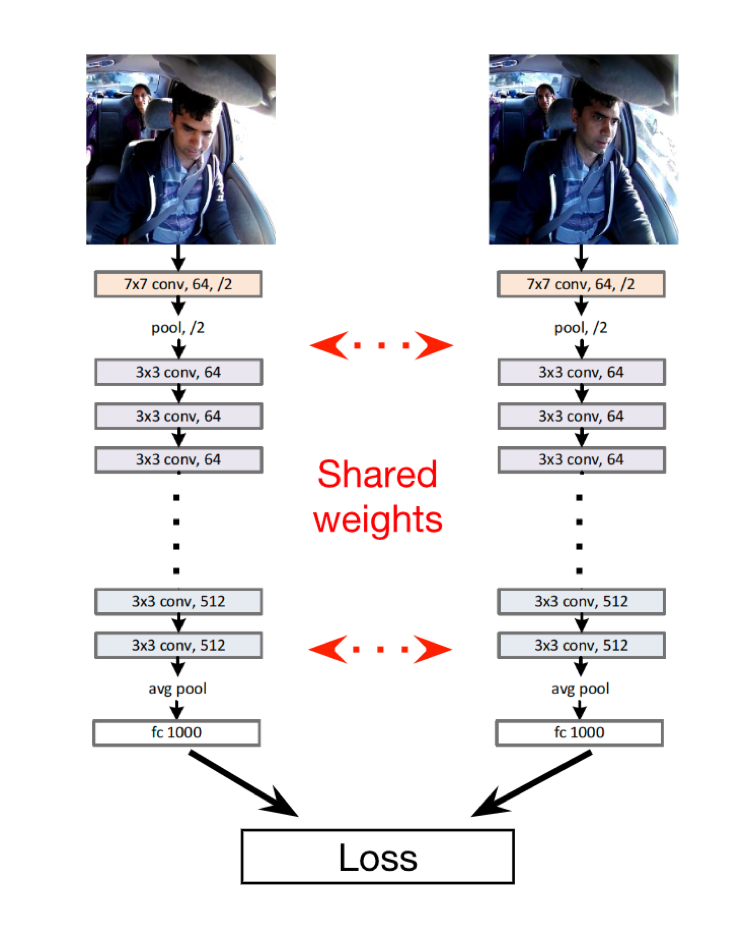
「ドライバーは運転中、常時道路に目を向けている」という想定に基づき、推測時にランダムな2枚のフレームをペアリングします。Siameseネットワーク設定では、ほぼすべての重みが共有されるため、出力される特徴量ベクトルの演算は1回だけです。その結果が、追加される最小限の演算オーバーヘッドになります。また、ロバスト性を向上させるため、過去にペアリングした複数のフレームペアから予想した結果をもとに、平均化させることができます。このアプローチは、過去にペアリングしたフレームペアNセットにサイズ2の1D畳み込みを適用するとも考えることができます。ナウトの実験から、LSTMまたはSiameseネットワークを使用することで、精度が著しく向上することが分かりました。Siameseネットワークのアプローチの方が、演算効率が良く、シンプルなトレーニング方法です。
今後の展望
ナウトのインテリジェント安全運転システムは、2017年4月に発売されて以来、ドライバーの安全教育やアラートを強化し、道路の安全を日々守っています。近年のAIの進化によりナウトは著しい成長を遂げていますが、やるべきことは、まだまだたくさんあります。ナウトは積極的に新機能を追加することで、精度、効率性、運転体験など全体的な機能向上を目指しています。実環境に影響する複雑な問題を解決したい方、またAIを使った交通安全に興味をお持ちの方は、ナウトの採用ページをご覧ください!


